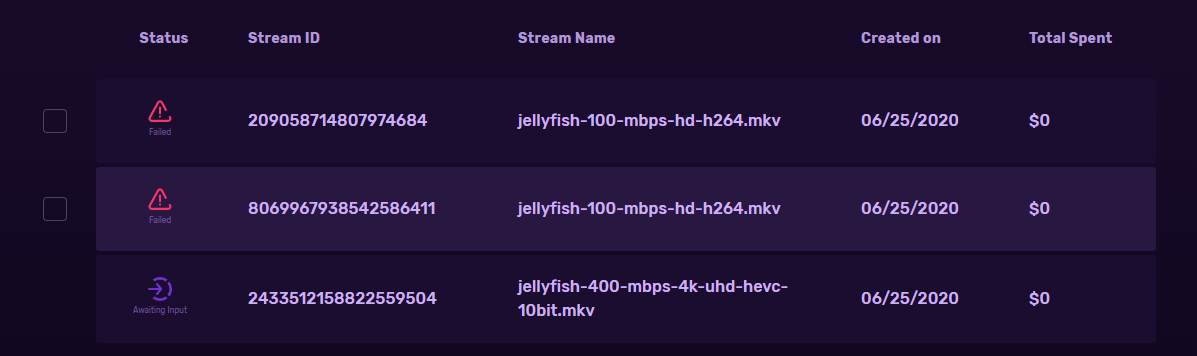
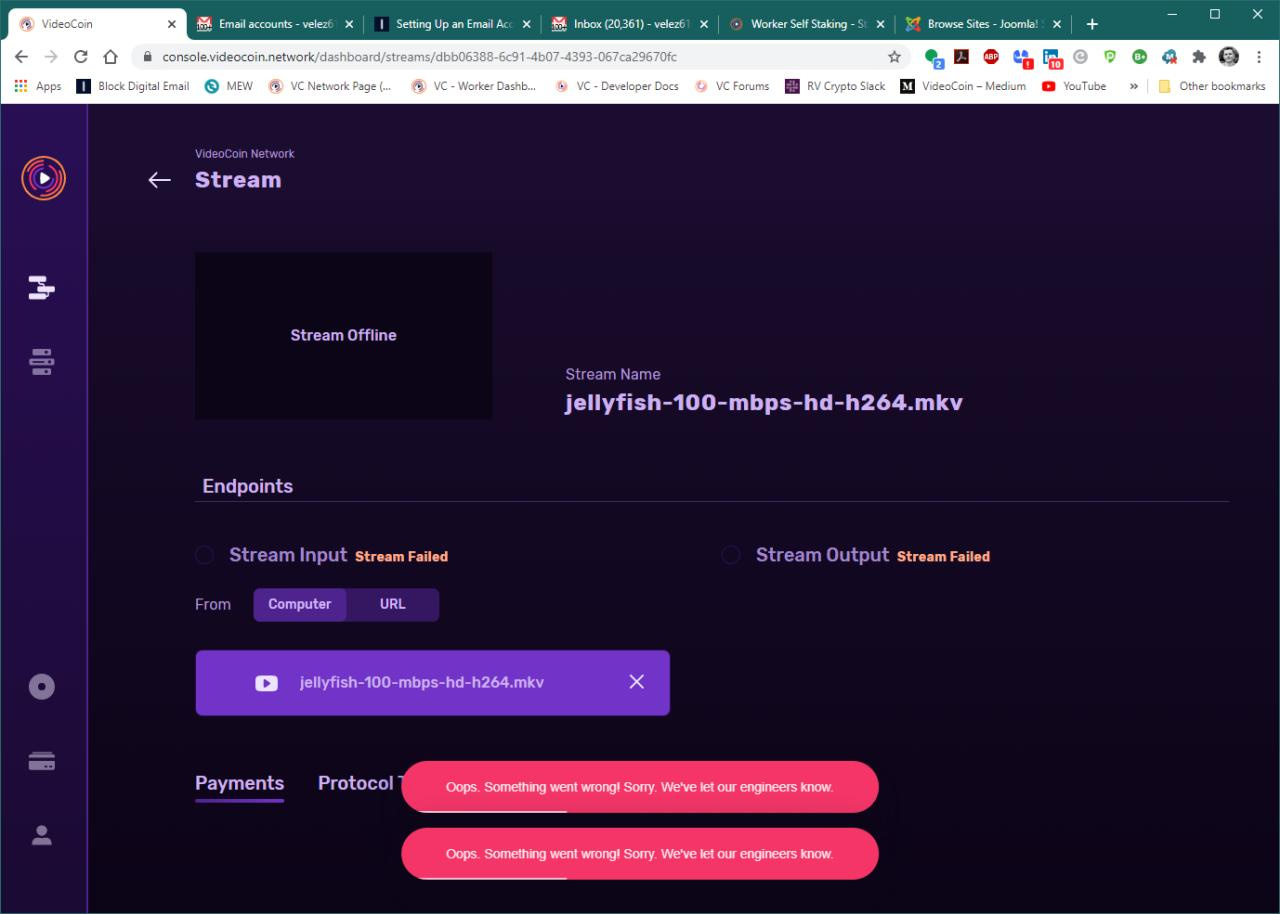
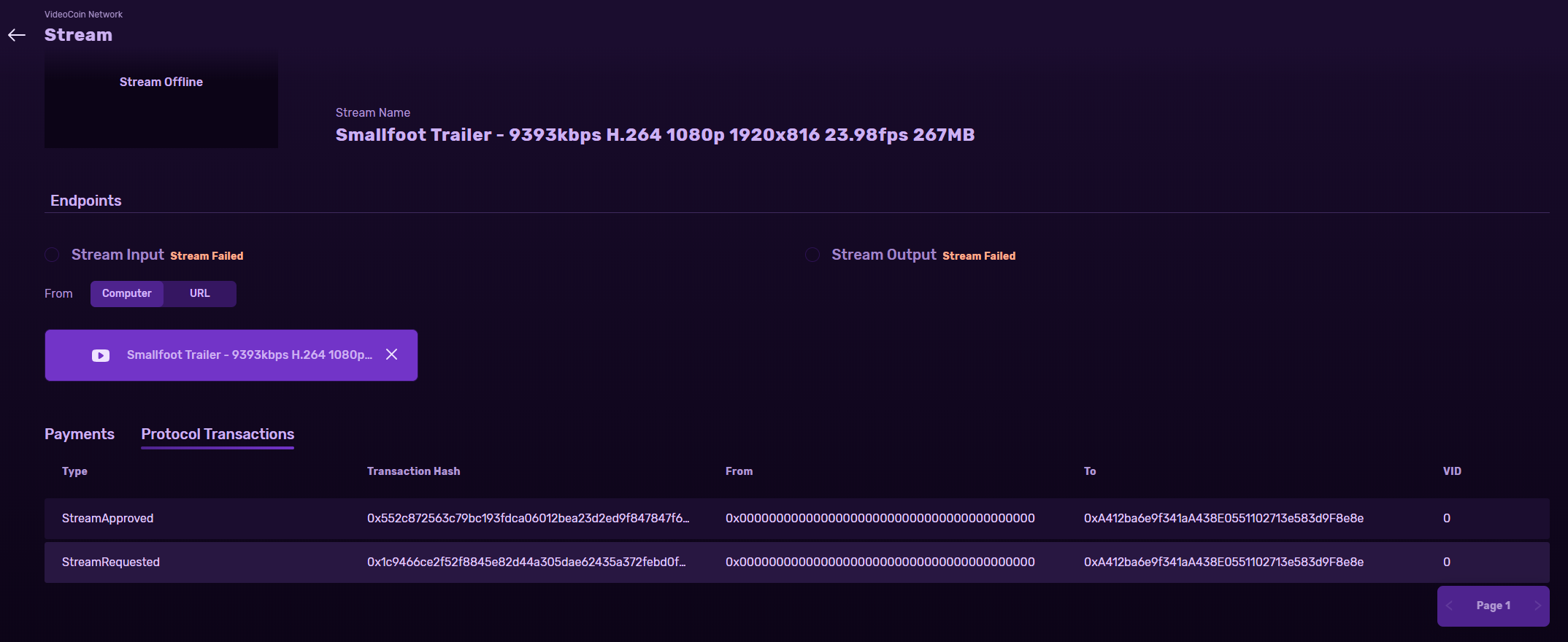
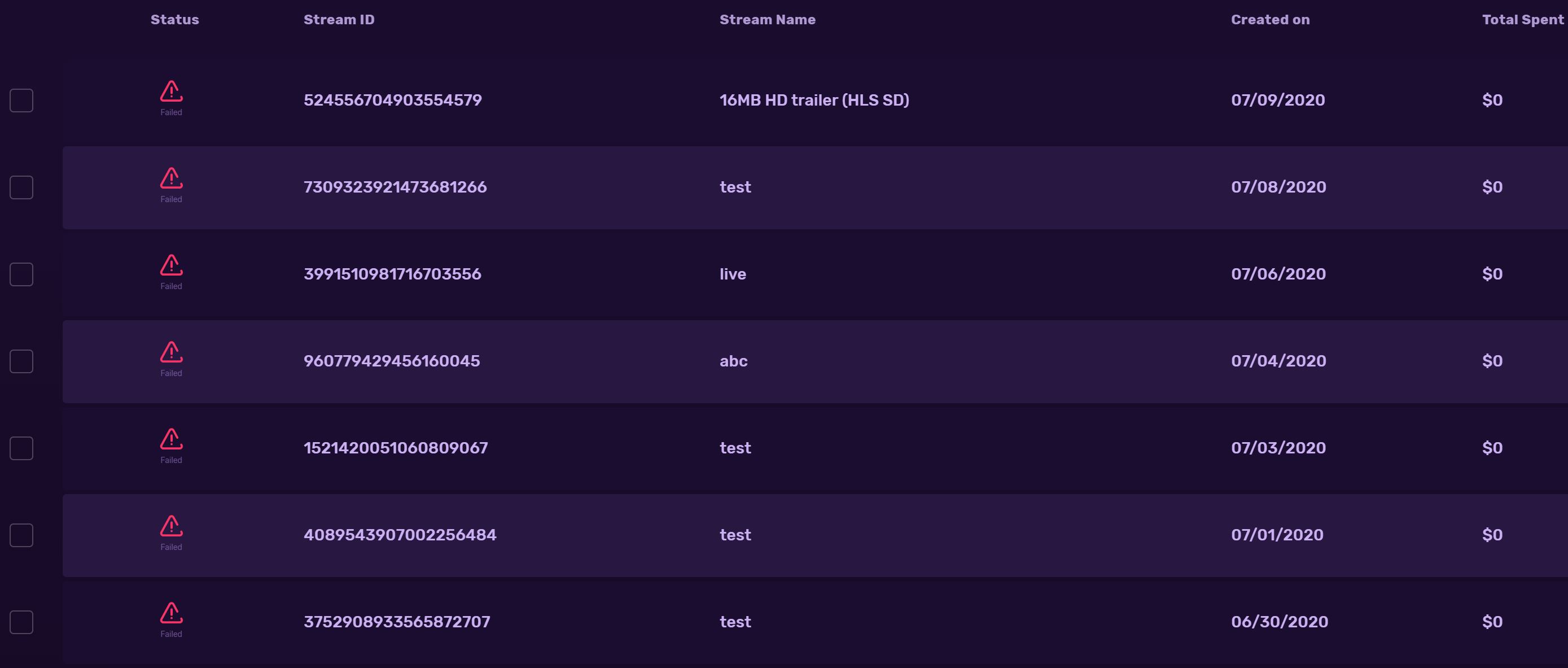
I suspect the failure in Santiago’s setup may be something to do with very high bitrate streams (400, 100mbps) and networking bandwidth bottlenecks that are causing time-outs in the transcode pipeline . We will try reproduce the issue and update.
Based on my own test results over the last few weeks it feels like its not to do with the input or output settings. Before the previous update where pools needed to rebond, almost all my tests were successful. Post rebonding, every test (same variables), have failed and I cannot produce any successful stream with any setting or file type.
So do you think that it’s an upload bottleneck for large bitrate streams? In other words, my ISP throughput is insufficient to accomodate real-time upload / transcode? Why can’t the file be incrementally uploaded / transcoded to accommodate a variety of bandwidths?
@BluBlu@Santiago_Velez
We found a bug related to VID balance calculation that was causing failure of transcoding for some of the stream-ids that you posted.
Please test again and post the stream-id, if you still see the issue
@Ram_Penke
I would like to test a stream after potential bug fix, now it says minimum 10$ credits needed to start stream. The 9.84$ in credits seems like plenty to run a good amount of tests. Can I have the minimum amount lowered to run a few tests or should I purchase more credits?
A note to @BluBlu@Santiago_Velez and others who are using tranascoing:
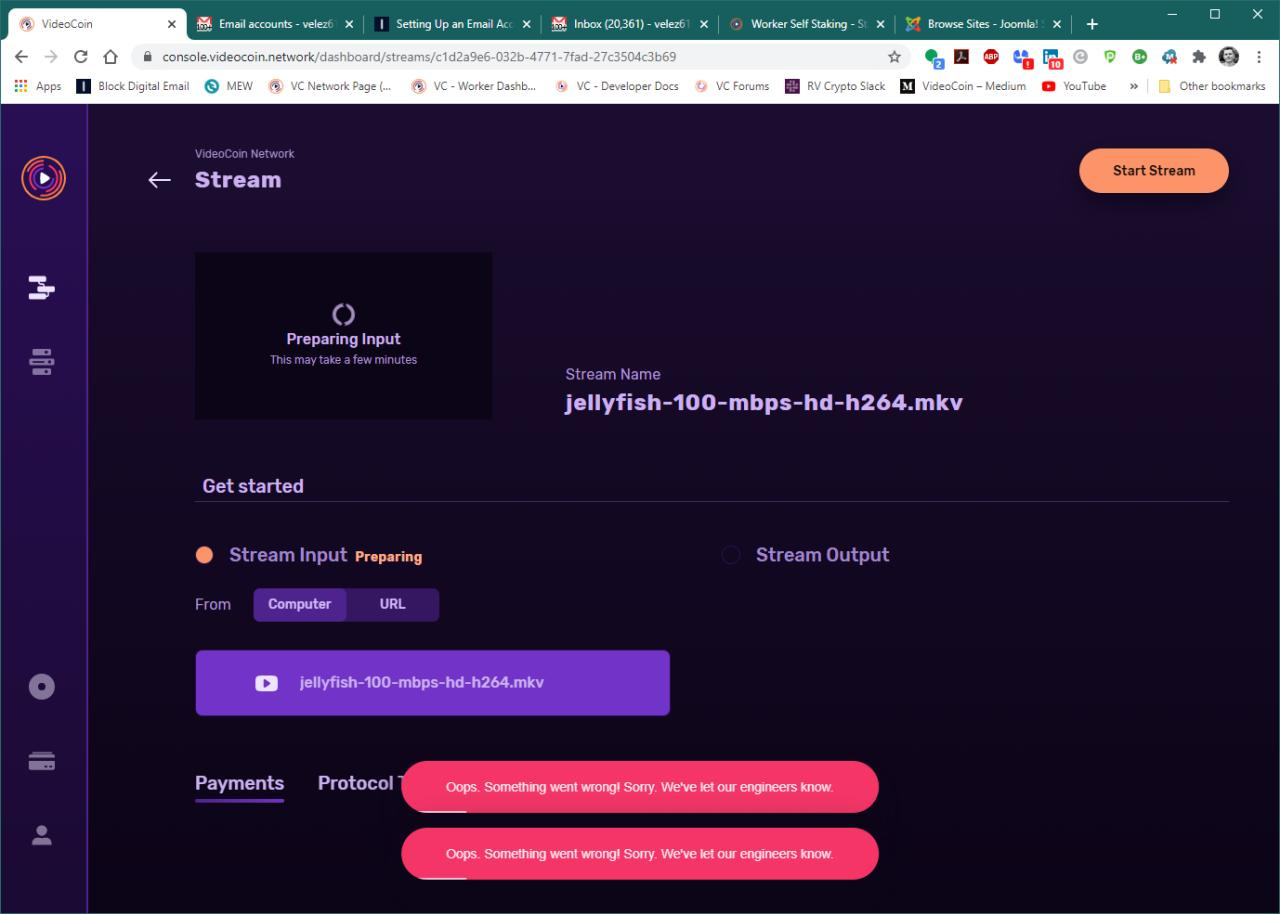
Currently the file transcode forces a wait of around 5 minutes after the last chunk of the file is transcoded. Please wait for it to finish and show play button in the preview window instead of cancelling.
It will be fixed soon.
I have successfully run 3 livestreams all leading up to zone0 workers being pulled up to do 100% of the work. My question is what is the limiting factor in our worker machines that cannot handle any of the livestreaming workload? I tested 950mbps download/30mbps upload on my bandwidth connection. Is it an upload issue?
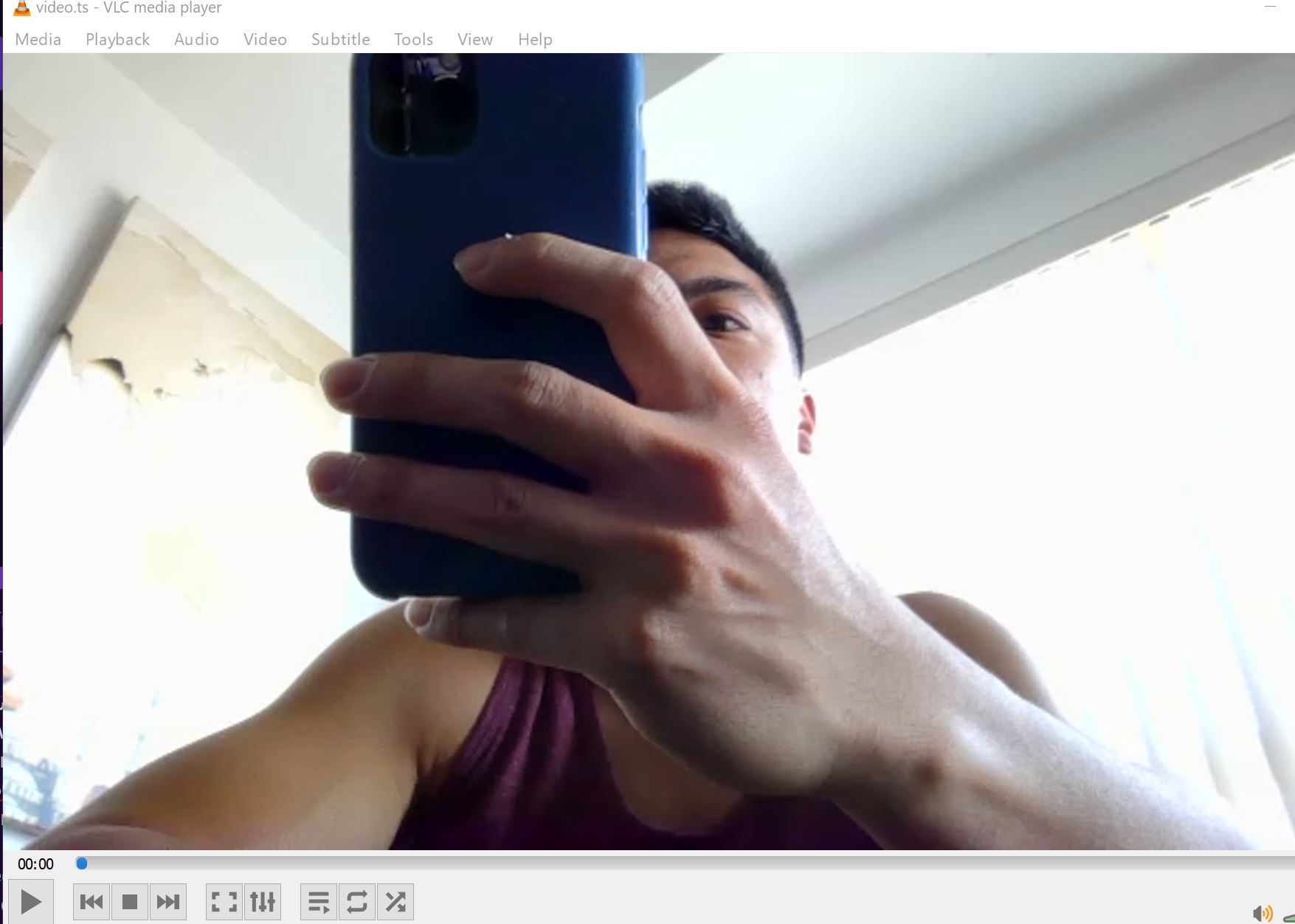
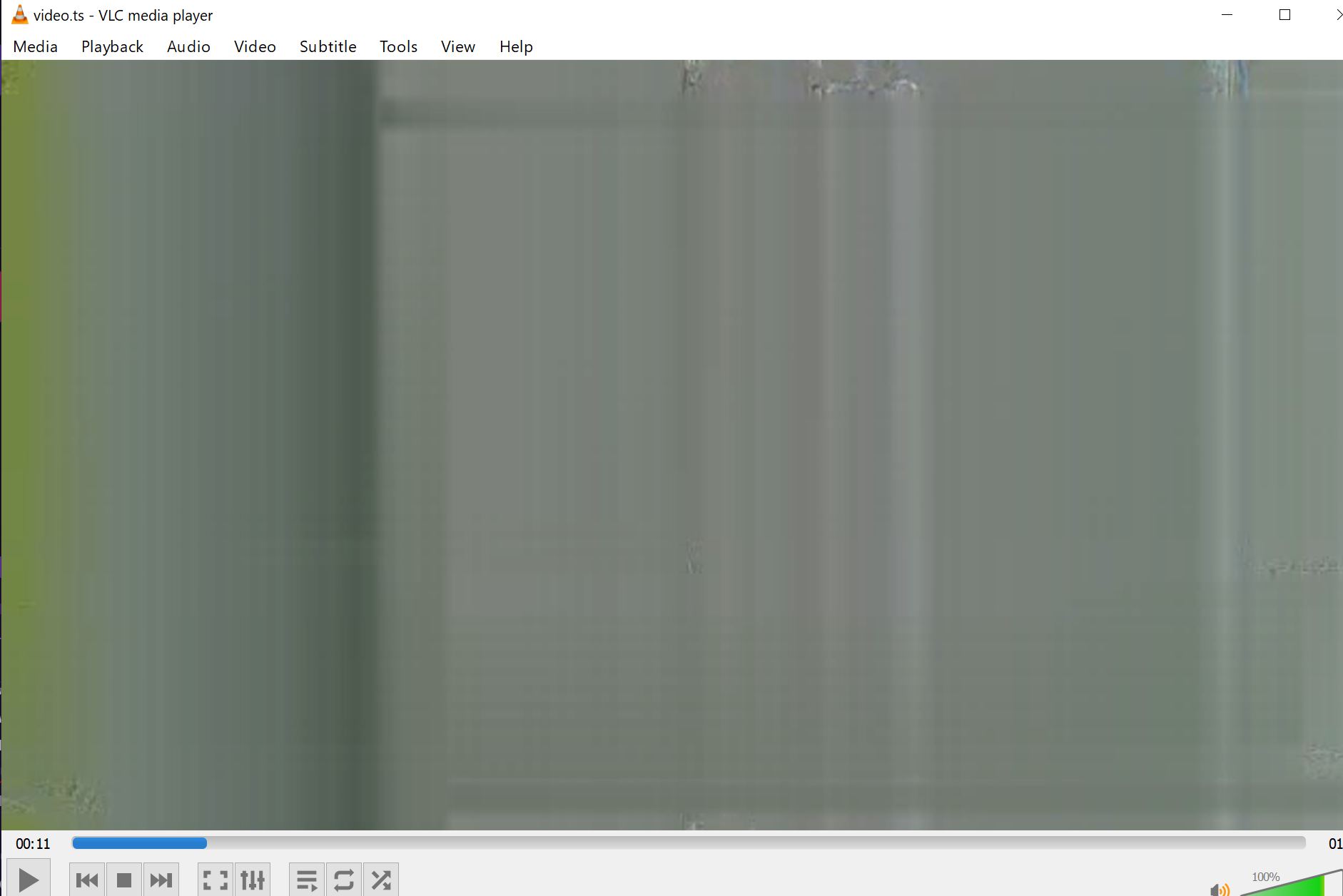
Secondly both of my recent livestream tests have resulted in bad video images with working audio. Both times the video works perfectly fine in the beginning and after a few seconds it goes bad. I have a video of the output showing this. Granted it could be with the laptop used to livestream but highly doubtful and will try with a different input source to confirm. Doesn’t allow me to upload video files onto the forum so I will attach the screen capture.
@BluBlu Please share the stream-ids of the three live streams. I will ask the video-infra team to analyze it further and shed light on why zone-0 workers are selected.
Regarding video corruption, the whole pipeline uses lossless (tcp) transport. The video-infra team will be able to compare source stream captured at ingest and transcoded stream and find if the corruption is introduced during transcoding.
Would it also be possible to explain why 100% of the work for these 3 streams all went to genesis pool while BluBlu and BDC pools ended up with 0%? Is that working as intended?
All work should bypass Zone - 0 to Workers unless there are extenuating circumstances (like insufficient independent workers, a time constraint by publishers, ultra-low bandwidth bottlenecks). If the algorithm is biased towards Genesis how will the network incentives to to workers to promote organic growth?
@Santiago_Velez@BluBlu
The worker selection algorithm already implements what you are looking for i.e. it selects independent workers first and then selects zone-0 if there are no independent workers. While selecting independent workers It follows the selection algorithm as described in the following medium post:
Following is my feedback for the current behavior that you observed in worker selection.
videocoin-geneis-0 is an independent worker i.e. it is not a Zone-0 worker. As more workers join the network, we expect, the delegated staking spreads across the workers and weight of the videocoin-geneis-0 will reduce. It’s purpose is to kick-start delegated staking and not to grab work.
Zone-0 workers are started only if there are not enough external/independent workers available. These workers contain a ‘dot’ under delegated and direct stakes columns in explorer worker page
As you know, the main feature of VideoCoin network is distributed transcoding. It will launch multiple workers to perform transcoding of a single file and you may see a mix of zone-0 and independent workers, when there are not sufficient independent workers.
As the worker selection algorithm uses a probabilistic fairness model which distributes work among workers based on total-stake, we need to run tests long enough to observe the correctness of operation instead of couple of isolated tests.
All the worker work assignement data is recorded on the blockchain. We can analyze the data any time and assess the correctness of worker selection algorithm.
Following is the snapshot of explorer worker page, when I started 3 transcoding sessions in parallel. As you may know, ‘busy’ state indicates the worker assigned a job.assignment